
|
武汉大学学报(理学版)
|
|
|
|
|


热点文章
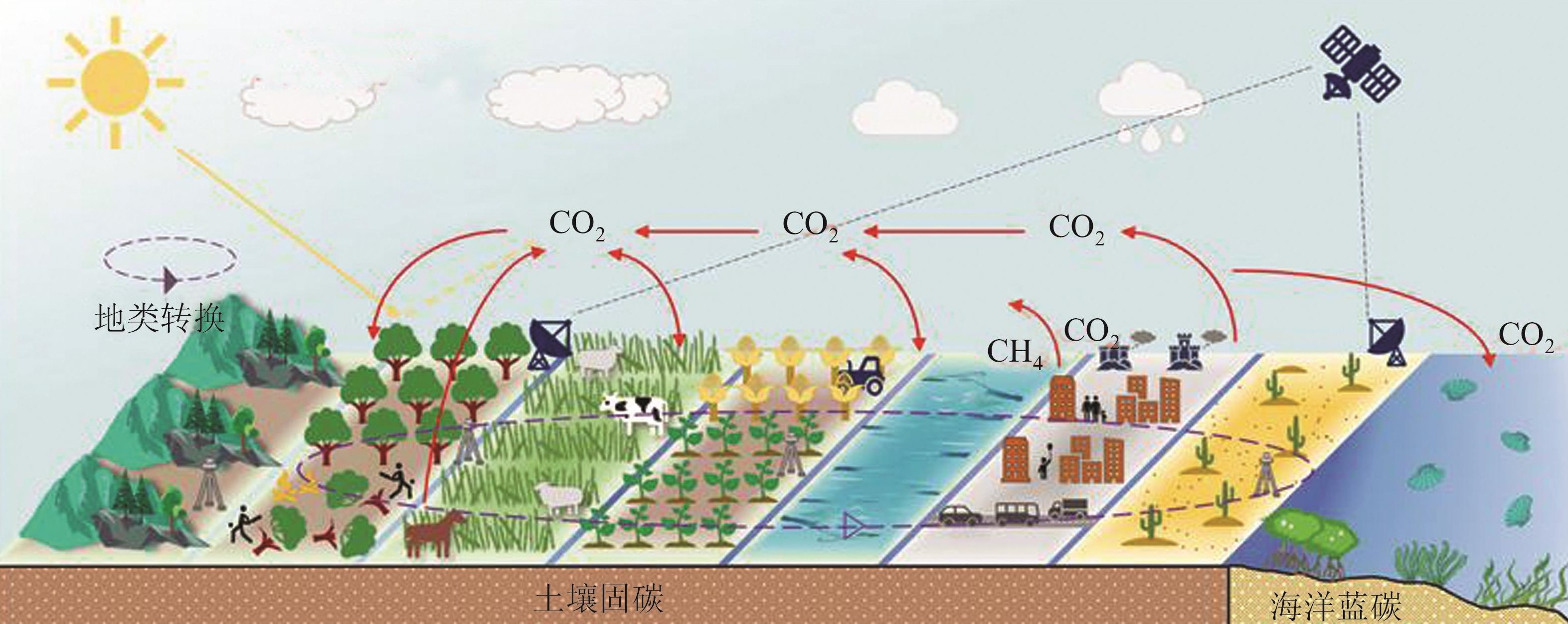
MORE- 基于“碳中和”目标的土地利用研究进展与思考 揣小伟
- 图模互补:知识图谱与大模型融合综述 黄勃 等
- 茵陈原儿茶酸乙酯对非酒精性脂肪肝的作用及机制 沈婉莹 等
- 电能存储与转换技术研究的机遇与挑战 彭创
- 高效稳定的碱性氢氧化反应电催化剂设计策略 安露露 等
- Mn基NASICON型钠离子电池正极材料研究进展 杨晨光 等
- 陶瓷隔膜厚度对磷酸铁锂电池安全性的影响 刘伯峥 等
- 基于多特征融合多任务的射频指纹识别方法 熊松磊 等
排行榜  更多
更多
- 0 1 图模互补:知识图谱与大模型融合综述 8433
- 0 2 智能网联汽车安全防护技术研究综述 2473
- 0 3 蛋白质的化学修饰策略 2386
- 0 4 Mn基NASICON型钠离子电池正极材料研究进展 2129
- 0 5 低贵金属含量酸性析氧催化剂研究进展 1925
- 0 6 图像分割方法综述 1839
- 0 7 杂交水稻育种技术的研究进展 1771
- 0 8 静电纺PVDF纳米纤维膜的工艺参数优化及压电性能 1660
- 0 9 用于残留农药检测的碳量子点荧光探针研究进展 1585
- 10 高效稳定的碱性氢氧化反应电催化剂设计策略 1468
查看更多



快捷入口
- 作者投稿
- 专家审稿
- 编辑办公
更多
- 最新文章
- 优先出版
- 过刊浏览
- 视频速递
2025年71卷第3期
电化学储能
“据最新报道,聚偏氟乙烯-六氟丙烯基复合电解质在锂电池固态电解质领域取得研究进展,有望提升固态锂电池性能。”摘要:聚偏氟乙烯-六氟丙烯(PVDF-HFP)凭借其高介电常数和优异的热稳定性,在锂电池固态电解质领域展现出广阔的应用前景,但存在机械强度低、与高电压正极兼容性差以及离子电导率低等问题。引入填料制备PVDF-HFP基复合电解质,可以增强电解质的机械性能,并通过与聚合物基体和锂盐的相互作用,提高电解质的电化学稳定性并优化离子传输。简要介绍了锂电池PVDF-HFP基复合电解质的离子传输机理及填料类型,系统阐述了填料在抑制锂枝晶生长、提高电化学稳定性和离子电导率方面的作用效果与研究进展,并总结当前面临的挑战和不足,展望了未来研究的发展方向,旨在为固态锂电池的性能提升及其应用提供参考。关键词:PVDF-HFP基复合电解质;填料;锂枝晶抑制;电化学稳定窗口;离子电导率136|67|0更新时间:2025-07-04-
钾离子电池生物质衍生碳材料负极研究进展 AI导读
“生物质衍生碳材料作为钾离子电池负极材料,优化电化学性能策略,推动大规模储能应用。”摘要:生物质衍生碳材料因工作电压低、循环稳定性好、来源广泛且环境友好等优点,被用作钾离子电池(KIBs)负极材料。然而,钾离子在碳材料中嵌入/脱嵌动力学过程迟缓以及电极材料的初始库仑效率低等问题,阻碍了其在大规模储能领域的实际应用。本文总结了生物质衍生碳材料负极在KIBs中的应用,梳理了生物质衍生碳材料的前驱体分类、制备方法及储钾机制,从结构改性、杂原子掺杂和复合材料设计三个方面详细分析了其用于KIBs负极材料的电化学性能优化策略,并展望了该领域未来的发展趋势。关键词:钾离子电池;负极材料;生物质;碳材料;储能;改性策略68|31|0更新时间:2025-07-04 - “在绿色能源领域,研究人员利用深共晶溶剂开发出高性能超级电容器,实现了高电压、低自放电和长循环稳定性。”摘要:深共晶溶剂是一类由氢键供体和氢键受体构成的新型绿色试剂。将三水合乙酸钠-尿素共晶溶剂(SU)作为钠离子储能电解质,通过调整水的加入量,得到具有优异的电化学性能的超级电容器。在兼具高离子电导率(31.89 mS/cm)和低黏度(4.88 mPa·s)的SU-7电解液中,该超级电容器获得高达2.1 V的稳定工作电压窗口、低自放电率(32.79%的电压保持率)、优越的倍率性能(1~5 A/g,比电容保持率64.24%,能量密度保持率49.74%)以及超过20 000次循环的长期稳定性。该研究推进了以SU为代表的绿色水系深共晶电解质在高性能超级电容器中的应用。关键词:深共晶溶剂;绿色电解液;超级电容器;电化学性能66|30|0更新时间:2025-07-04
- “在能源存储领域,研究人员采用恒电势电沉积法制备了聚苯胺/多孔碳@碳布复合柔性电极,显著增强了电极的倍率性能和循环稳定性,为柔性超级电容器的发展提供了新思路。”摘要:采用恒电势电沉积法在碳布(CC)上原位电沉积聚苯胺/多孔碳(PANI/PC),得到PANI/PC@CC复合柔性电极,系统探讨了制备条件对PANI/PC@CC结构及其电容性能的影响。结果表明,多孔碳的引入显著增强了PANI/PC@CC的倍率性能和循环稳定性,同时PANI/PC@CC具有良好的柔韧性。最佳条件下制备的PANI/PC@CC在电流密度1 mA/cm2时的比电容高达3 042.8 mF/cm2,20 mA/cm2时的倍率性能达到88.0%,15 mA/cm2时2 000次充放电循环后的电容保持率达到97.6%,表明其具有良好的电容性能。由PANI/PC@CC组装的柔性对称超级电容器也展示出优异的电化学性能和柔韧性。关键词:柔性电极;柔性超级电容器;聚苯胺;多孔碳99|66|0更新时间:2025-07-04

查看更多
- 虚拟专辑
- 精选图片

大语言模型

杂交水稻

机器学习

区块链

图染色和图标号理论及算法

分析化学

环境科学

生物学
查看更多
- 地址:湖北省武汉市武昌区武汉大学文理学部本科生院楼北楼504
- 联系电话:027-68756952 Email:whdz@whu.edu.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备09064830号-19
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies
- 总访问量:1109588 今日访问量:32
批量引用
0